Training CLIP on COCO from Scratch
CLIP is contrastive language image pretraining and it is a great method that aligns the text and the image modality together. What does it mean to align these two? Consider for example, the image of a cat on a table, and the corresponding caption that describes that image. To align these two together means to map both the image and the text sentence to a space, where both of them are close to each other in terms of their properties. Intuitively, doing so will arrange these different images and the text sentences that describe them in such a way that similar images will have same properties because similar images might have same caption, like “a cat on a table” and “a cat playing in garden”. The word cat is common to both of them, hence the image feature vector will contain useful properties of the visual description of the cat. Also, it will likely capture relationships between different attributes or objects as well, for ex - “an image of a cat on a table”, captures the relationship between cat and the table that might be visible from the image. The image feature vector will also capture the relationship between those, and hence aligning those might be very beneficial. Also, one usually has access to large amounts of (image, text) pairs that can be used for training such a model.
Dataset
The original CLIP was trained on huge amounts of closed source data, but there are many open-source alternatives like COCO. I dowloaded the COCO (Common Objects in Context) Dataset which contains roughly 591k training images and 25k validation images having captions annotated along with the images. There are multiple captions that have been annotated with every image.
Some examples are given below…



For the textual caption preprocessing, I removed the punctuations and created a word to index mapping, which maps every word to an index. The total vocabulary size (i.e number of distinct words) after preprocessing was roughly 29k.
For the image preprocessing, I used a resized the image to (224, 224) and normalized it, by using the following transformation
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
Implementation
For the image encoder, I used the resnet18 model (pretrained on ImageNet) and the textual encoder was a transformer model with 4 attention layers
class CLIP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.backbone = ResNetEncoder(config.backbone, pretrained=True)
self.img_lin = nn.Linear(512, config.query_dim)
self.final_conv = nn.Conv2d(64, 1, kernel_size=3, padding=1)
self.text_encoder = nn.ModuleList([TransformerLayer(config) for _ in range(config.num_tr_layers)])
self.embeddings = nn.Parameter(torch.randn(config.vocab_len, config.query_dim))
self.text_lin = nn.Linear(config.query_dim, config.query_dim)
def forward(self, img, text):
feats = self.backbone(img)
final_feat = feats[4].mean(2).mean(2) # (b, 512)
img_feat = self.img_lin(final_feat)
img_feat = img_feat / torch.sqrt(torch.sum(img_feat ** 2, -1, keepdim=True))
text_emb = self.embeddings[text]
for i, layer in enumerate(self.text_encoder):
text_emb = layer(text_emb, text_emb)
text_feat = self.text_lin(text_emb.mean(1))
text_feat = text_feat / torch.sqrt(torch.sum(text_feat ** 2, -1, keepdim=True))
score_mat = img_feat @ text_feat.T
return score_mat
The forward function returns the score matrix of shape (B, B) which contains the alignment between the ith image feature and the jth text feature. To align these, the elements along the diagonal of the matrix should be high and the rest should be low, assuming the elements in the batch are different from each other, i.e it is safe to assume that one img, text pair is different from the other and hence should not be aligned with others.
We can use a cross-entropy loss here, by interpreting the elements of the score_mat as unnormalized logits, once along the row and once along the column, thereby interpreting this as a classification task of classifying a specific feature vector of the image modality to the feature vectors of the text modality and vice-verca.
def compute_loss(self, batch):
img, text = batch['img'], batch['text']
score_mat = self(img, text)
labels = torch.arange(len(text)).to(text)
loss1 = F.cross_entropy(score_mat, labels)
loss2 = F.cross_entropy(score_mat.T, labels)
loss = (loss1 + loss2) / 2
return {"loss": loss}
Experiments
I used a batch size of 1024 (256 * 4 GPUS), with a learning rate of 1e-4. The other hyperparameters were
learning_rate: 0.0001
batch_size: 256
query_dim: 256
mha_heads: 2
num_tr_layers: 4
attention_emb_dim: 256
backbone: 'resnet18'
dataset_type: coco
dataset_config : '/ssd_scratch/cvit/keshav/coco/annotations/captions_train2017.json'
ckpt_dir: '/ssd_scratch/cvit/keshav/coco_ckpts'
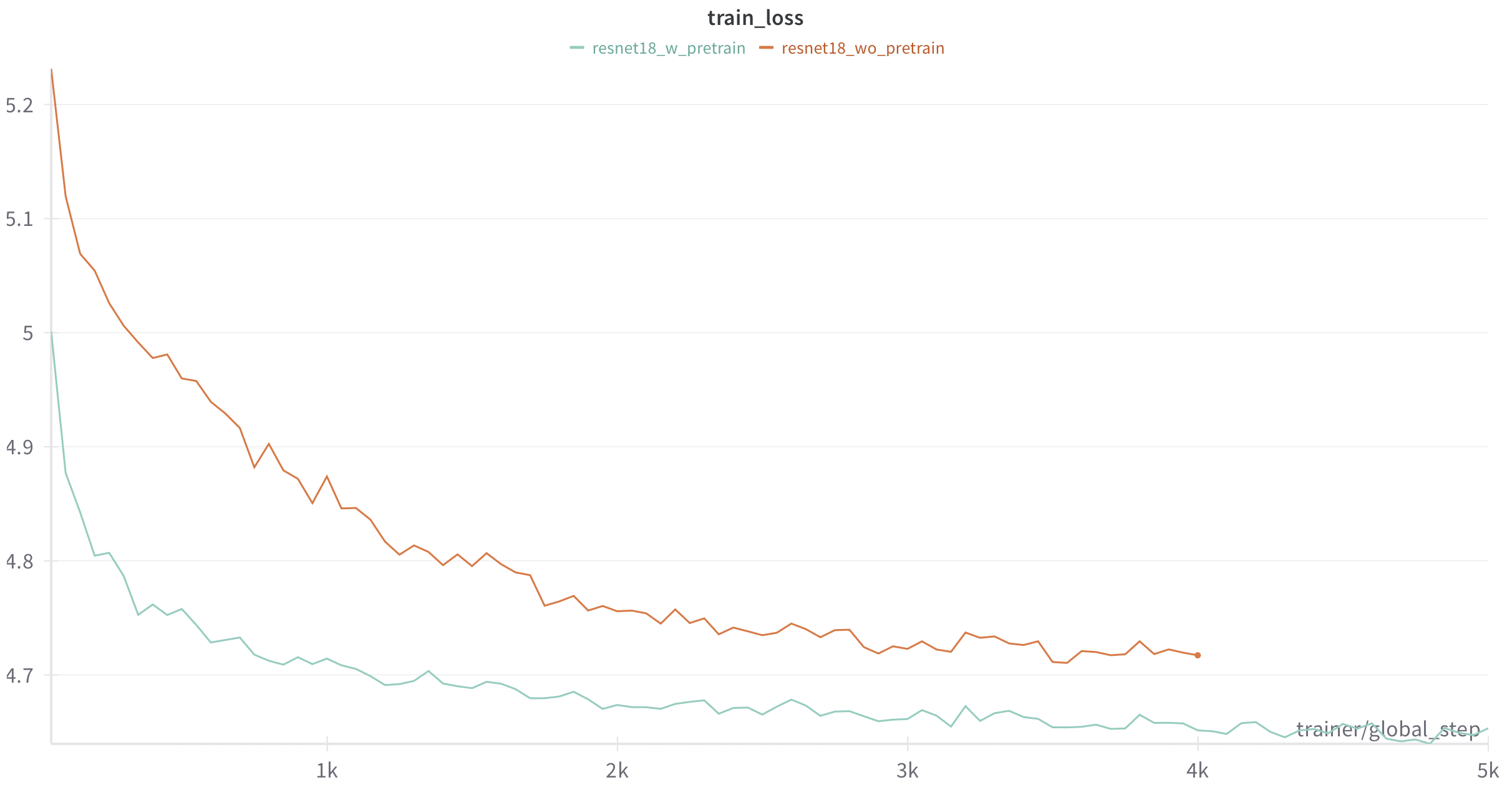
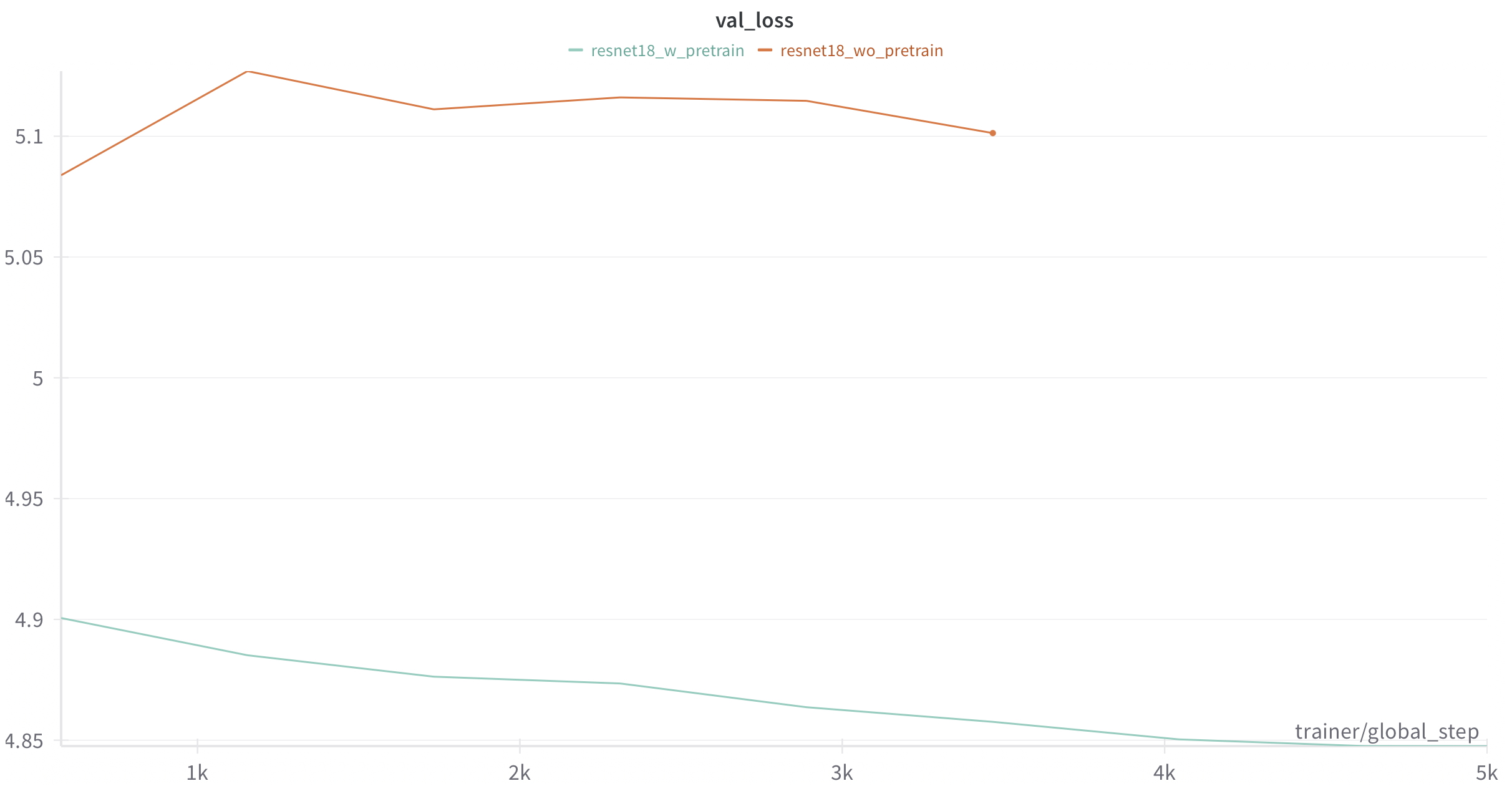
I was curious to see the effect of resnet pretraining and hence ablated on it. The model starts from an initial loss of ln(1024) = 5.56 and goes down to roughly 4.6, wheras without pretraining converges much slower and interestingly the validation loss without pretraining almost remains constant.
Here are the training curves…
Inference
To see the performance of the model, I took an image of an apple using my phone on my table and calculated the score matrix with some of the candidate captions listed below…

texts = ["a black motorcycle parked in front of a garage",
"a banana on a table",
"an apple on a table",
"a surfer on water",
"many kids lined up in a row",
"a person holding a tennis racket",
"a person riding a skateboard",
"a person riding a bicycle",
"a person holding a baseball bat",
"a person eating fruits",
"many fruits on a table",
"some fruits in a basket",
"a red apple on a table",
"a green apple on a table",]
The corresponding score matrix (1 x 14) comes out to be
tensor([[-0.0020, 0.9602, 0.9375, -0.0371, -0.2046, -0.0504, -0.0581, -0.0164,
-0.0588, 0.8394, 0.9811, 0.9867, 0.8763, 0.9812]], device='cuda:0')
Interestingly, sentences with fruits in them, either the word itself or some examples of fruits like banana seem to be aligned with the image feature. Importantly, anything else which is not connected to an apple or a fruit comes out to be negative.